Appendix A - Elastic Block Store (EBS)¶
EBS can be used to store HDB data, and is fully compliant with kdb+.
It supports all of the POSIX semantics required.
Amazon EBS allows you to create storage volumes and attach them to Amazon EC2 instances. Once attached, you can create a file system on top of these volumes, run a database, or use them in any other way you would use block storage. Amazon EBS volumes are placed in a specific Availability Zone (AZ) where they are automatically replicated to protect you from the failure of a single component. All EBS volume types offer durable snapshot capabilities and are designed for 99.999% availability.
Amazon EBS provides a range of options that allow you to optimize storage performance and cost for your workload. Seven variants of the Elastic Block Store (EBS) are all qualified by
kdb+: gp2, gp3, io1, io2, and io2 Block Express are SSD-based volumes that offer different
price/performance points, st1 and sc1 are HDD-based volumes comprised of traditional drives.
Unlike ephemeral SSD storage,
SSD-backed volumes include the highest performance Provisioned IOPS SSD (io2 and io1) for latency-sensitive transactional workloads and General Purpose SSD (gp3 and gp2) that balance price and performance for a wide variety of transactional data. HDD-backed volumes include Throughput Optimized HDD (st1) for frequently accessed, throughput intensive workloads and the lowest cost Cold HDD (sc1) for less frequently accessed data. Details on Volume Sizes, MAX IOPS, MAX THROUGHPUT, LATENCY, and PRICE for each EBS volume type are available on AWS.
The new io2 Block Express architecture delivers the highest levels of performance with sub-millisecond latency by communicating with an AWS Nitro System-based instance using the Scalable Reliable Datagrams (SRD) protocol, which is implemented in the Nitro Card dedicated for EBS I/O function on the host hardware of the instance. Block Express also offers modular software and hardware building blocks that can be assembled in many ways, giving you the flexibility to design and deliver improved performance and new features at a faster rate. For more information on io2 Block Express, see this AWS Blog.
EBS-based storage can be dynamically provisioned to any other EC2 instance via operator control. So this is a good candidate for on-demand HDB storage. Assign the storage to an instance in build scripts and then spin them up. (Ref: Amazon EBS)
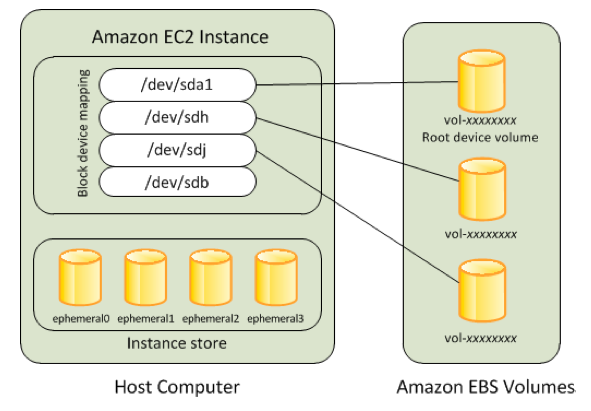
Customers can enable Multi-Attach on an EBS Provisioned IOPS io2 or io1 volume to allow a volume to be concurrently attached to up to sixteen Nitro-based EC2 instances within the same Availability Zone. Multi-Attach makes it easier to achieve higher application availability for applications that manage storage consistency from multiple writers. Each attached instance has full read and write permission to the shared volume. To learn more, see Multi-Attach technical documentation.
Data Lifecycle Manager for EBS snapshots provides a simple, automated way to back up data stored on EBS volumes by ensuring that EBS snapshots are created and deleted on a custom schedule. You no longer need to use scripts or other tools to comply with data backup and retention policies specific to your organization or industry.
Amazon EBS provides the ability to save point-in-time snapshots of your volumes to Amazon S3. Amazon EBS Snapshots are stored incrementally: only the blocks that have changed after your last snapshot are saved, and you are billed only for the changed blocks. If you have a device with 100 GB of data but only 5 GB has changed after your last snapshot, a subsequent snapshot consumes only 5 additional GB and you are billed only for the additional 5 GB of snapshot storage, even though both the earlier and later snapshots appear complete.
With lifecycle management, you can be sure that snapshots are cleaned up regularly and keep costs under control. Simply tag your EBS volumes and start creating Lifecycle policies for creation and management of backups. Use Cloudwatch Events to monitor your policies and ensure that your backups are being created successfully.
Elastic Volumes is a feature that allows you to easily adapt your volumes as the needs of your applications change. Elastic Volumes allows you to dynamically increase capacity, tune performance, and change the type of any new or existing current generation volume with no downtime or performance impact. Easily right-size your deployment and adapt to performance changes.
Amazon EBS encryption offers seamless encryption of EBS data volumes, boot volumes and snapshots, eliminating the need to build and manage a secure key management infrastructure. EBS encryption enables data at rest security by encrypting your data volumes, boot volumes and snapshots using Amazon-managed keys or keys you create and manage using the AWS Key Management Service (KMS). In addition, the encryption occurs on the servers that host EC2 instances, providing encryption of data as it moves between EC2 instances and EBS data and boot volumes. For more information, see Amazon EBS encryption in the Amazon EC2 User Guide.
EBS is carried over the local network within one availability zone. Between availability zones there would be IP L3 routing protocols involved in moving the data between zones, and so the latencies would be increased.
EBS may look like a disk, act like a disk, and walk like a disk, but it doesn’t behave like a disk in the traditional sense.
There are constraints on calculating the throughput gained from EBS (performance numbers below are from 2018 - soon to be updated):
-
There is a max throughput to/from each physical EBS volume. This is set to 500 MB/sec for io1 and 160 MB/sec for
gp2. Agp2volume can range in size from 1 GB to 16 TB. You can use multiple volumes per instance (and we would expect to see that in place with a HDB). -
There is a further limit to the volume throughput applied, based on its size at creation time. For example, a GP2 volume provides a baseline rate of IOPs geared up from the size of the volume and calculated on the basis of 3 IOPs/per GB. For 200 GB of volume, we get 600 IOPS and @ 1 MB that exceeds the above number in (1), so the lower value would remain the cap. The burst peak IOPS figure is more meaningful for random, small reads of kdb+ data.
-
For
gp2volumes there is a burst level cap, but this increases as the volume gets larger. This burst level peaks at 1 TB, and is 3000 IOPS. that would be 384 MB/sec at 128 KB records, which, again is in excess of the cap of 160 MB/sec. -
There is a maximum network bandwidth per instance. In the case of the unit under test here we used
r4.4xlarge, which constrains the throughput to the instance at 3500 Mbps, or a wire speed of 430 MB/sec, capped. This would be elevated with larger instances, up to a maximum value of 25 Gbps for a large instance, such as forr4.16xlarge. -
It is important note that EBS scaled linearly across an entire estate (e.g. parallel peach queries). There should be no constraints if you are accessing your data, splayed across different physical across distinct instances. e.g. 10 nodes of
r4.4xlargeis capable of reading 4300 MB/sec.
kdb+ achieves or meets all of these advertised figures. So the EBS network bandwidth algorithms become the dominating factor in any final
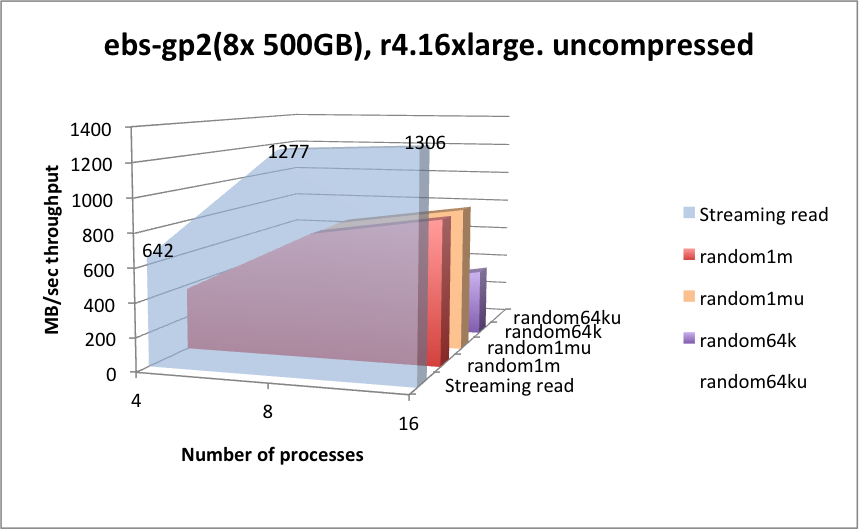
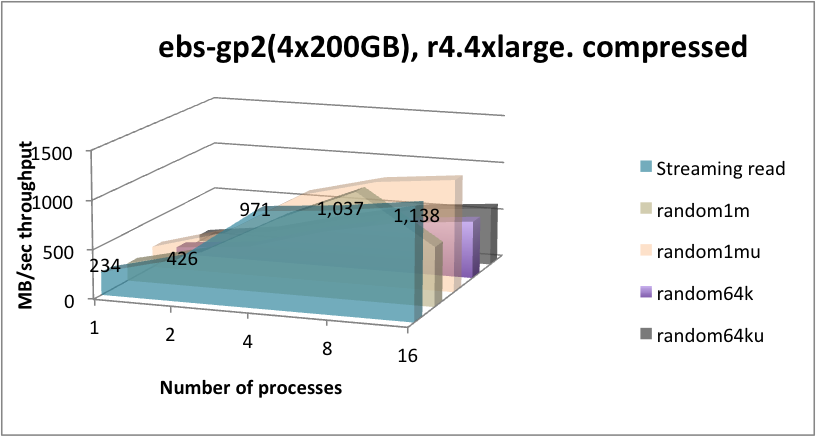
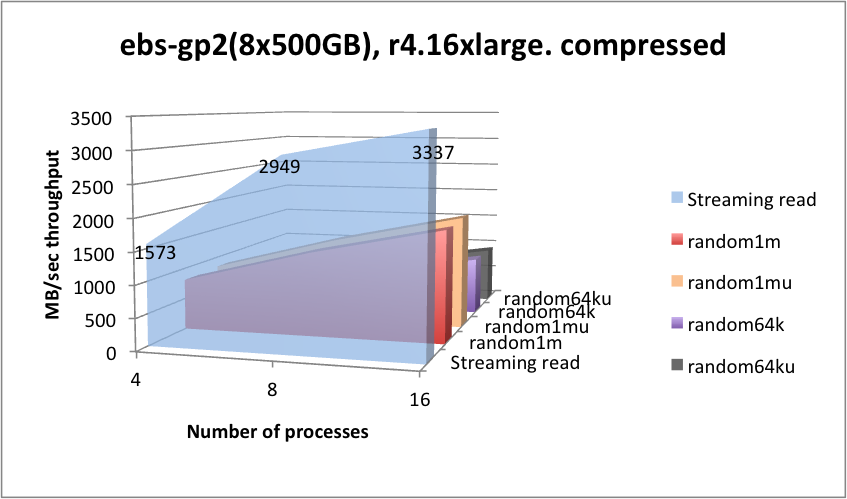
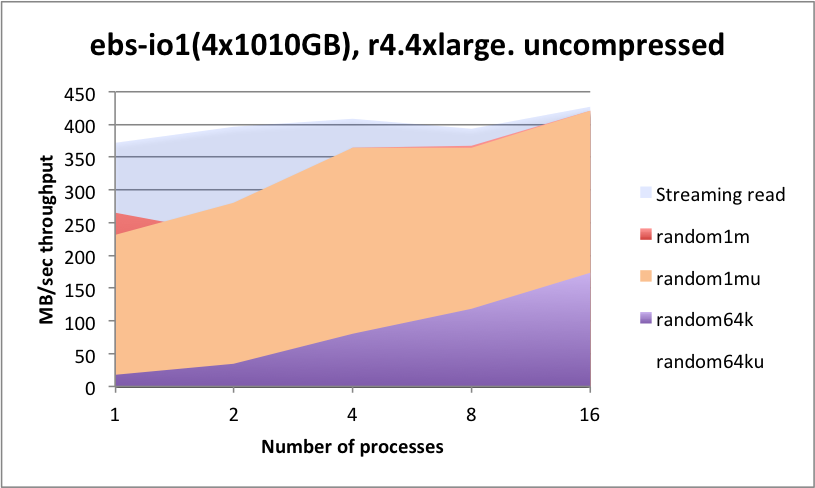
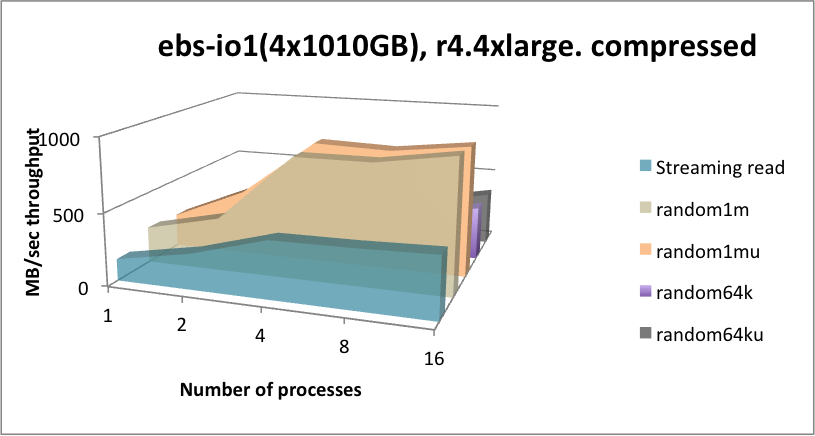
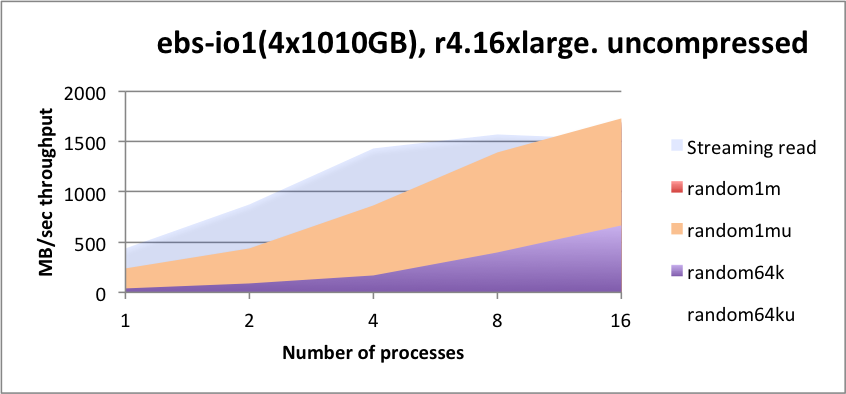
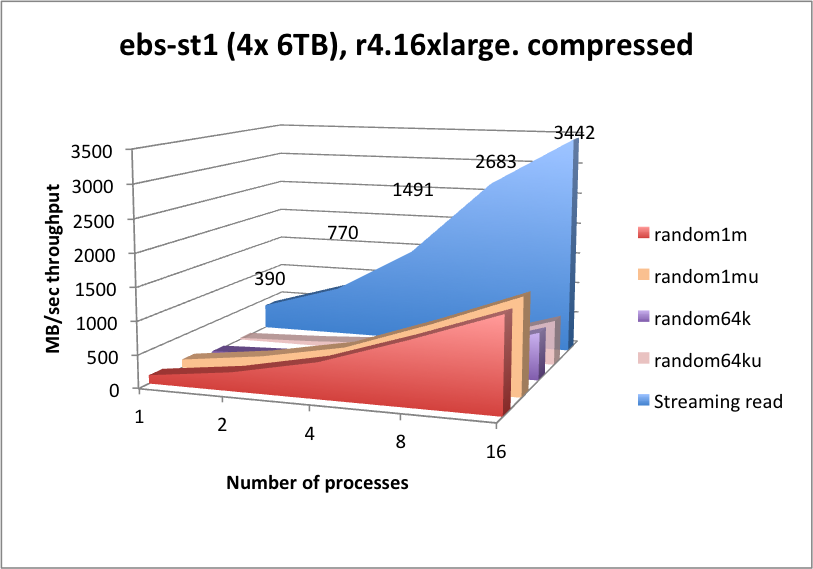
In 2018, Kx Systems conducted performance tests on r4.4xlarge instances with four 200-GB volumes, each with one xfs file system per volume, therefore using four mount points (four partitions). To show higher throughputs, r4.16xlarge instances with more volumes: eight 500-GB volumes were tested. Comparisons were made on gp2 and io1 as well. For testing st1 storage, four 6-TB volumes were tested. Note: The faster nitro instances and io2, io2 Block Express, and NVMe storage has not been tested yet. The results below are a bit dated, but still provide useful information.
EBS-GP2¶
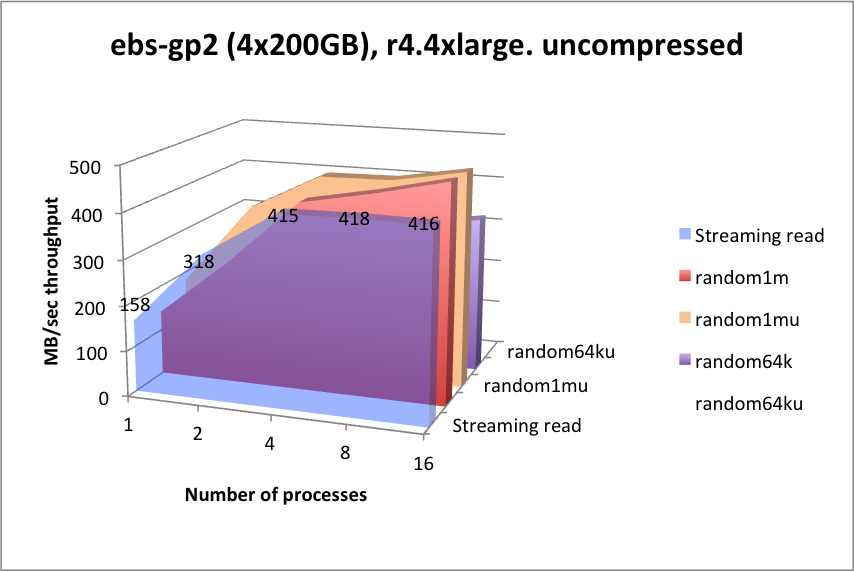
| function | latency (mSec) | function | latency (mSec) |
|---|---|---|---|
hclose hopen |
0.004 | ();,;2 3 |
0.006 |
hcount |
0.002 | read1 |
0.018 |
EBS GP2 metadata operational latencies - mSecs (headlines)
EBS-IO1¶
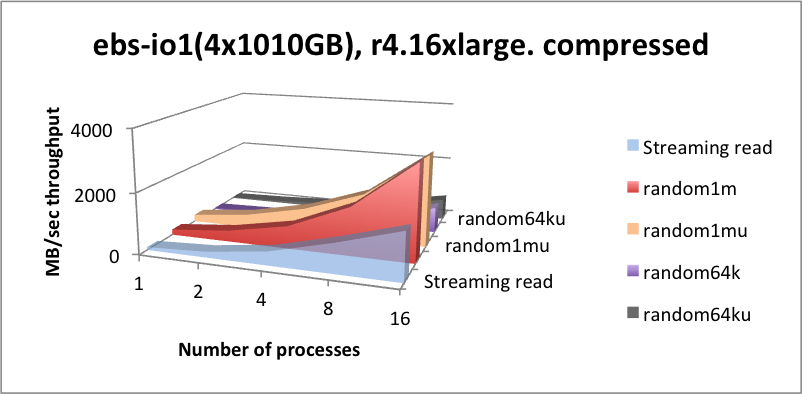
| function | latency (mSec) | function | latency (mSec) |
|---|---|---|---|
hclose hopen |
0.003 | ();,;2 3 |
0.006 |
hcount |
0.002 | read1 |
0.017 |
EBS-IO1 metadata operational latencies - mSecs (headlines)
EBS-ST1¶
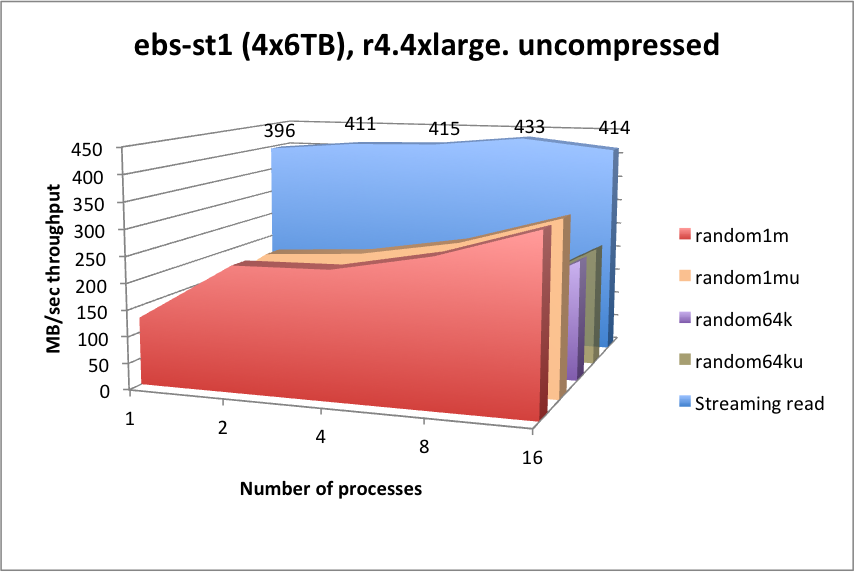
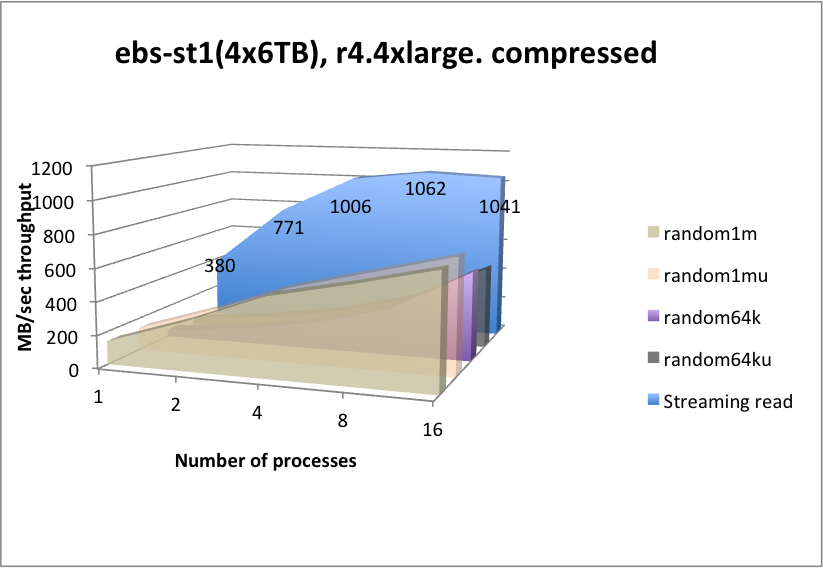
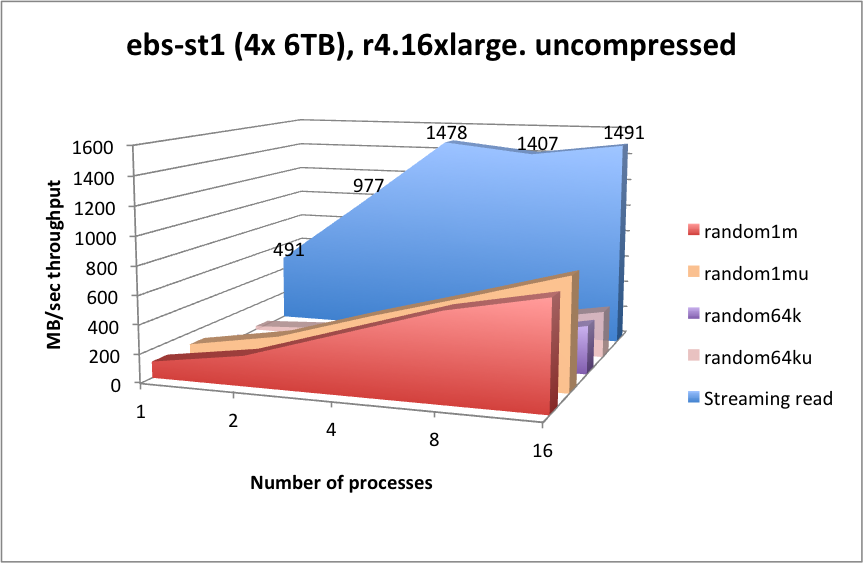
| function | latency (mSec) | function | latency (mSec) |
|---|---|---|---|
hclose hopen |
0.003 | ();,;2 3 |
0.04 |
hcount |
0.002 | read1 |
0.02 |
EBS-ST1 metadata operational latencies - mSecs (headlines)
Summary¶
kdb+ matches the expected throughput of the EBS configurations tested with no major deviations across all classes of read patterns required. At the time these tests were conducted, EBS-IO1 achieves slightly higher throughput metrics over GP2, but achieves this at a guaranteed IOPS rate. Its operational latency is lower for meta data and random reads. When considering EBS for kdb+, take the following into consideration:
-
Fixed bandwidth per node: in our testing cases, the instance throughput limit of circa 430 MB/sec for
r4.4xlargeis easily achieved with these tests. Contrast that with the increased throughput gained with the largerr4.16xlargeinstance. Use this precept in your calculations. -
There is a fixed throughput per GP2 volume, but multiple volumes will increment that value up until the peak achievable in the instance definition. kdb+ achieves that instance peak throughput.
-
Server-side kdb+ in-line compression works very well for streaming and random 1-MB read throughputs, whereby the CPU essentially keeps up with the lower level of compressed data ingest from EBS, and for random reads with many processes, due to read-ahead and decompression running in-parallel being able to magnify the input bandwidth, pretty much in line with the compression rate.
-
st1works well at streaming reads, but will suffer from high latencies for any form of random searching. Due to the lower capacity cost ofst1, you may wish to consider this for data that is considered for streaming reads only, e.g. older data.