Non-Transformed TSS¶
This page explains the Non-Transformed Temporal Similarity Search (Non-Transformed TSS) feature in KDB.AI.
If you're already familiar with this topic, you can skip ahead to the How to perform a Non-Transformed TSS search guide.
Non-Transformed TSS is a similarity search algorithm specific for time series data, with high precision: and measured up to 1 million data points. For a single series search, you can query extensive historical data using the
searchBy advanced option applied on splayed or partitioned tables running on external kdb+ databases.
For example usage, see our GitHub repository.
The key concepts to understand are:
- differences between Non-Transformed TSS and similarity search
- the benefits of Non-Transformed TSS on temporal data
- time series pattern matching.
Differences between Non-Transformed TSS and similarity search¶
Non-Transformed TSS differs from similarity search indexes in the following ways:
- There is no precomputation (index creation) involved.
- It significantly reduces the time from data insertion to first query, which is an advantage for fast-moving data.
Benefits of Non-Transformed TSS on temporal data¶
Non-Transformed TSS leverages the strengths of traditional vector similarity search and simultaneously addresses the unique challenges of temporal data in key areas such as:
- Specialized Temporal Data Analysis: offers a more precise and efficient method for analysing temporal data.
- Near Real Time Data Processing: provides a significant boost in speed as no index build is required; allows quicker queries and faster data analysis, essential in environments where near-real-time data processing is critical.
- Enhanced Accuracy and Recall: recognizes and interprets the patterns and trends inherent in temporal data leading to improved recall, accuracy, and precision.
- Ease of Use: operates on temporal data as is, no complex parameters need be passed in, no index needs to be built to search.
- Dynamic Searches: can be configured at run time unlike FAISS searches which require expensive and time-consuming index rebuild operations.
- Scalability and Adaptability: offers a scalable solution that can handle increasing amounts of time series data as it is memory and CPU efficient.
Time series pattern matching¶
Time series pattern matching refers to the process of identifying and recognizing specific patterns or trends within a time series data set. As time series is a sequence of data points collected over a period of time (where each data point is associated with a timestamp), the time series pattern matching involves searching for recurring patterns, anomalies, or specific shapes within the data.
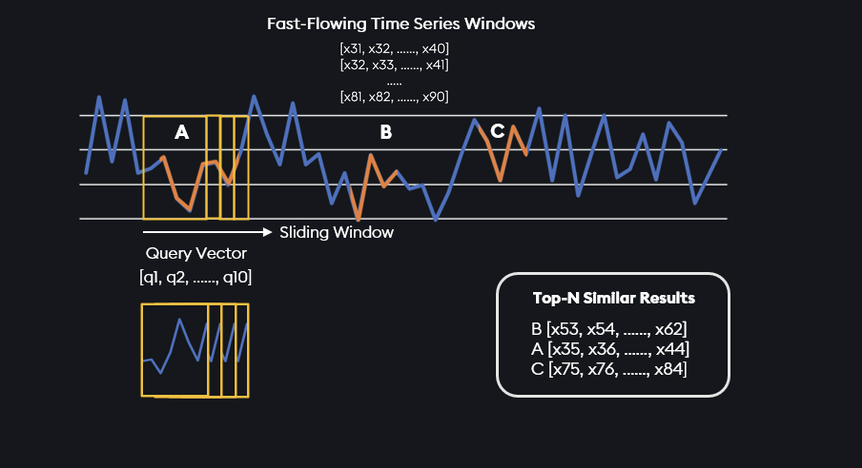
In the above example, we are searching for a query of 10 time points: [q1, q2, ..., q10] among a data of 60 time points: [x31, x32, ..., x90]. A sliding window of length 10, the same as the query is created and the length-60 data is scanned through the sliding windows and try to match with the query. The three most similar results, referring to the windows B, A and C are being output by the time series matching algorithm accordingly.
Pattern matching in time series data can be useful in various applications, such as event detection, anomaly detection, forecasting, and signal processing.
Next steps¶
Now that you are familiar with the Non-Transformed TSS concepts, you can:
- Perform a Non-Transformed TSS search.
- Explore use cases on the KDB.AI Learning hub.
- Download the pattern matching Jupyter Notebook and accompanying files at the repository on GitHub.
- Run the notebook directly in Google Colab.